Introduction
Finally it’s here, deep dive series of vRealize Orchestrator (vRO), previously known as vCenter Orchestrator (vCO). The purpose of this series is to explain and discuss developing custom workflows to automate IT processes. My plan is to go through the following:
- vRO Part 1 – Introduction
- vRO Part 2 – Action & Workflow
- vRO Part 3 – Presentation Layer
- vRO Part 4 – Log Handling, Throwing Exceptions and Fail-back
- vRO Part 5 – Introduction to Relationship Between vRO & vRA
- vRO Part 6 – Integration of vRO & vRA
I won’t be going through how to install/configure vRO, there are many blogs out there for reference. Rather, I will be deep diving into development side.
- Language to learn
- Object and Type
- Input, Output and Attribute
Language to learn
First of all, vRO is JavaScript based. So, if you are not familiar with this language, I suggest you to Google and read some basics with JavaScript, there are tons of resources out there!
Preparation
Before we start, let’s create a simple workflow for the exercises later:
Login to vRO, right click on folder and create a workflow:
Name it Sample Workflow, or something you would like to name:

Navigate to Inputs tab and click Add parameter:
Name it VM and for the Type, search for VC:VirtualMachine and Accept:

Go back to Schema, edit Scriptable Task and navigate to Visual Binding:
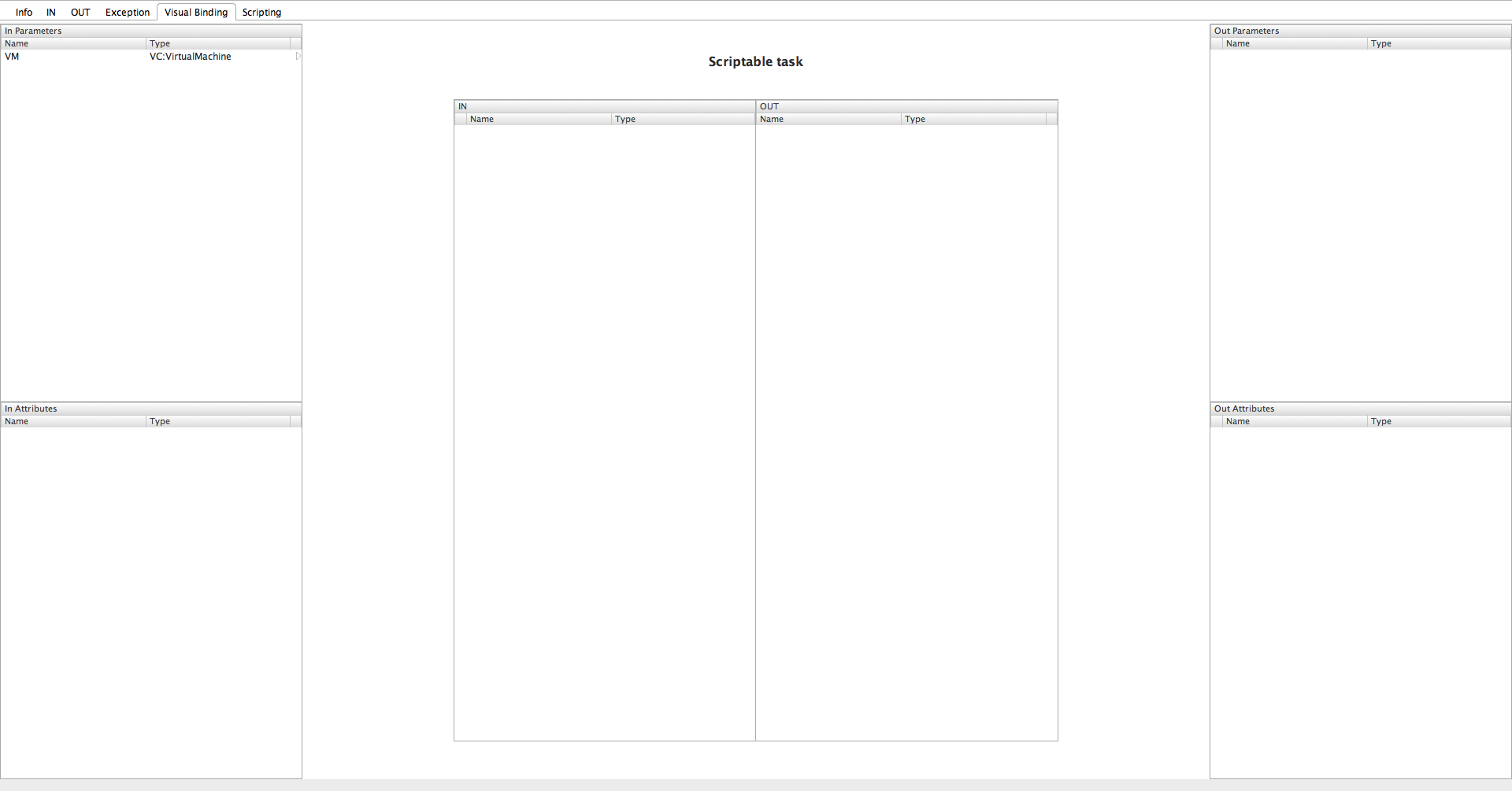
Drag VM and drop it in IN box:

Save and Close. You can safely ignore the validation for now.
So everything’s ready, let’s get started!
Object & Type
Starting with definition of object:
A JavaScript object is an unordered collection of variables called named values
In vRO, there are lots of predefined objects VMware created, for example, VC:VirtualMachine and to develop a workflow properly, you must get familiar with objects. Let me make it clear with an example, go back to the workflow created above, click edit on the scriptable task and navigate to Scripting tab:


On the left hand above corner, you will see the list of APIs in the box. Let’s search for VC:VirtualMachine and click Go to selection:
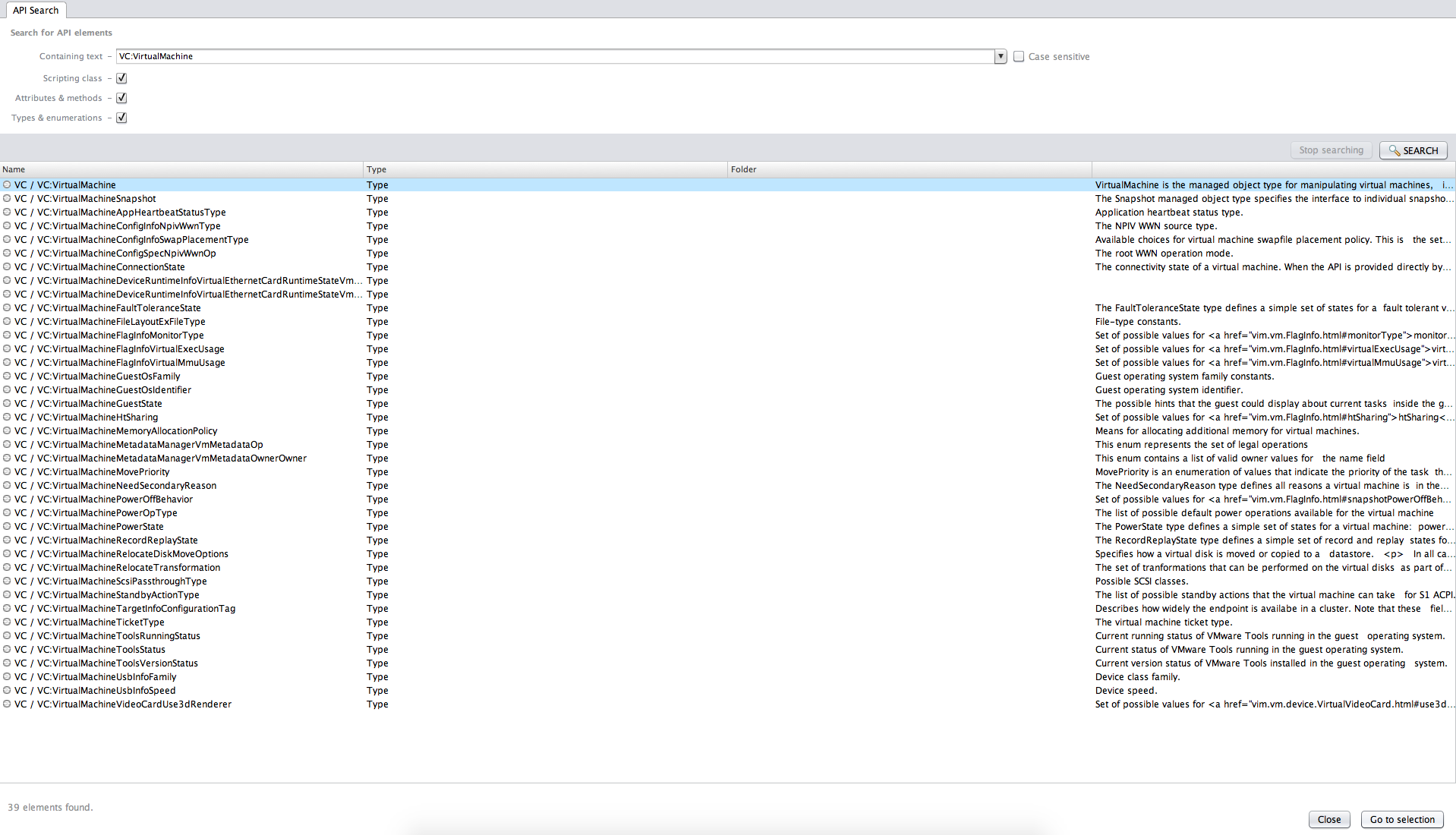
When you close the window, you will see:
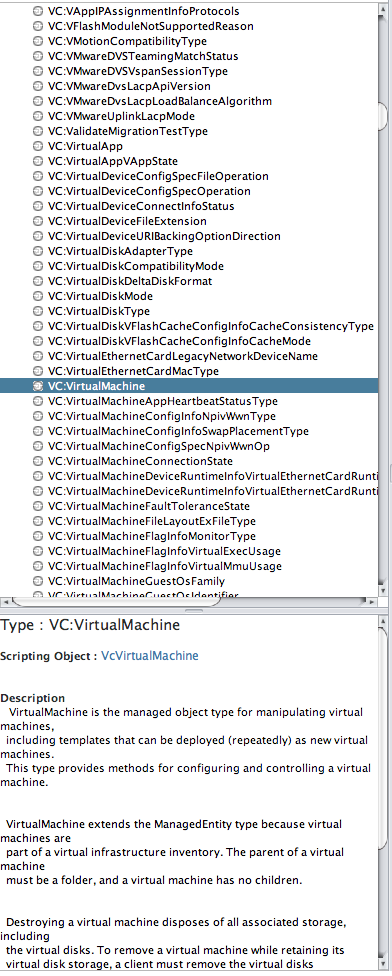
To view more details, click on VcVirtualMachine and expand:

Now, you will see the list of all properties and functions and this is where you will have to search and read all the time. From the screenshot above, empty rectangles represent property, filled rectangles represent functions and literally these are the form of VCVirtualMachine object where the type is VC:VirtualMachine. You can either call property or function like the following:
- Property => VC.datastore
- Function => VC.destory_Task()
In summary, an object has a type of xxx which consists of properties and functions.
To view more details, you can click on any properties or functions. For example, let’s click datastore:

One thing to note is, have a look at Return Type “Array of VcDatastore”. It means if you call for this property datastore, the return type will be Array of VcDatastore. I will be shortly going through type hence for now, let’s call some properties and output them on the log tab to see how they look like.
Edit the Scriptable task, navigate to Scripting tab and type System.log(VM.datastore);

Before moving on, I would like to emphasise one thing. When you call properties, it’s case-sensitive meaning if you type “System.log(VM.Datastore)” it will fail to call datastore property as it doesn’t exist! Ensure you look at the API box on the top left hand corner and type exactly what it says.
It’s time to run the workflow. Right click, run and you will see the workflow asking for an input VM.
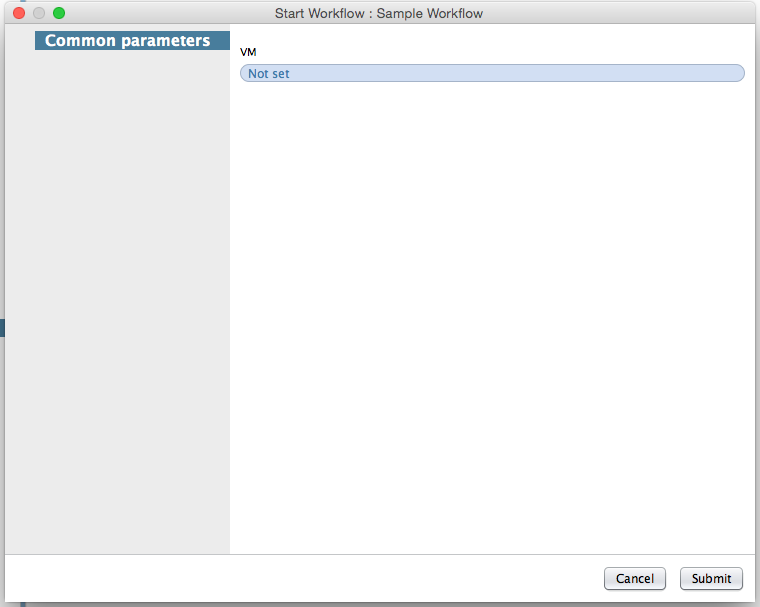
Click on Not set and select a VM and submit. Then, you will see VcDatastore type returned with the value which represents the name of datastore.

It will output VMFS volumes being used by this VM. That was quite simple, wasn’t it? The reason I wanted to go through objects is when you start developing workflows or utilising other pre-built workflows, you must understand and use correct objects. I will give you an example. Let’s say administrator from CompanyA is trying to automate the following process:
- Create a VM
- Move the VM to resource pool
- Power On
As there are already pre-built workflows available, he would want to use them instead of building from scratch. He created a workflow called “Custom VM Build” and put pre-built workflows into it. Then he will define 2 inputs for this workflow:
- VM, String
- ResourcePool, String
Then from Visual Binding, he will try and connect workflow inputs to pre-built ones and he will realise the operation is denied. The reason is simple, he hasn’t checked the inputs for 3 workflows above:
- Create a VM (pre-built)
- Input Type = VC:VirtualMachine
- Move the VM to resource pool (pre-built)
- Input Type = VC:VirtualMachine, VC:ResourcePool
- Power On (pre-built)
- Input Type = VC:VirtualMachine
Hence, he should have checked input types to match pre-built workflows’ inputs from the beginning. Make sure, know which objects with types you are planning to use, this looks very basic but this is the most important aspect.
Alternatively, he could have still used String inputs but then, extra scriptable task or action is required to convert String to either VC:VirtualMachine or VC:ResourcePool type. This will be discussed in the next series.
Input, Output and Attributes
Input
Time to look into inputs, outputs and attributes. Inputs and outputs are simple to understand, literally they are inputs and outputs to a workflow. Let’s re-cap the example above, I added an input called VM, VC:VirtualMachine to the Sample Workflow and this asked me to specify a VM when I ran it. The workflow prompts to ask users to put down inputs before running a workflow.
One thing to note is that the above statement doesn’t mean you must specify input value to run a workflow. I will show you why, go back to Orchestrator Client, edit Sample Workflow and navigate to Inputs tab:

Create one more input called “Cluster” and type to be “VC:ClusterComputeResource”:
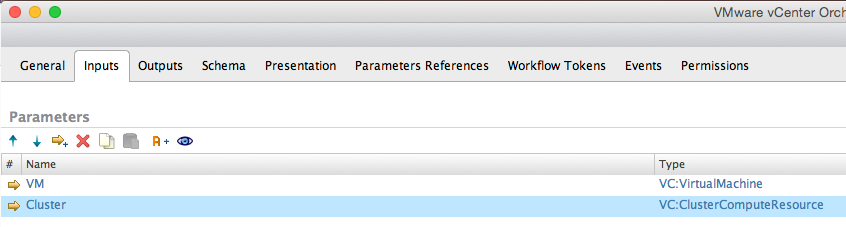
Save and Close, ignore the warning.
Now when you run it, the workflow will ask you to write down VM and Cluster:

Remember, the scriptable task in this workflow only looks for VM input and calls datastore property, i.e. System.log(VM.datastore). This means whether you specify Cluster value or not, it has no impact to the workflow. OK, why would you want to do this? I will give you another scenario.
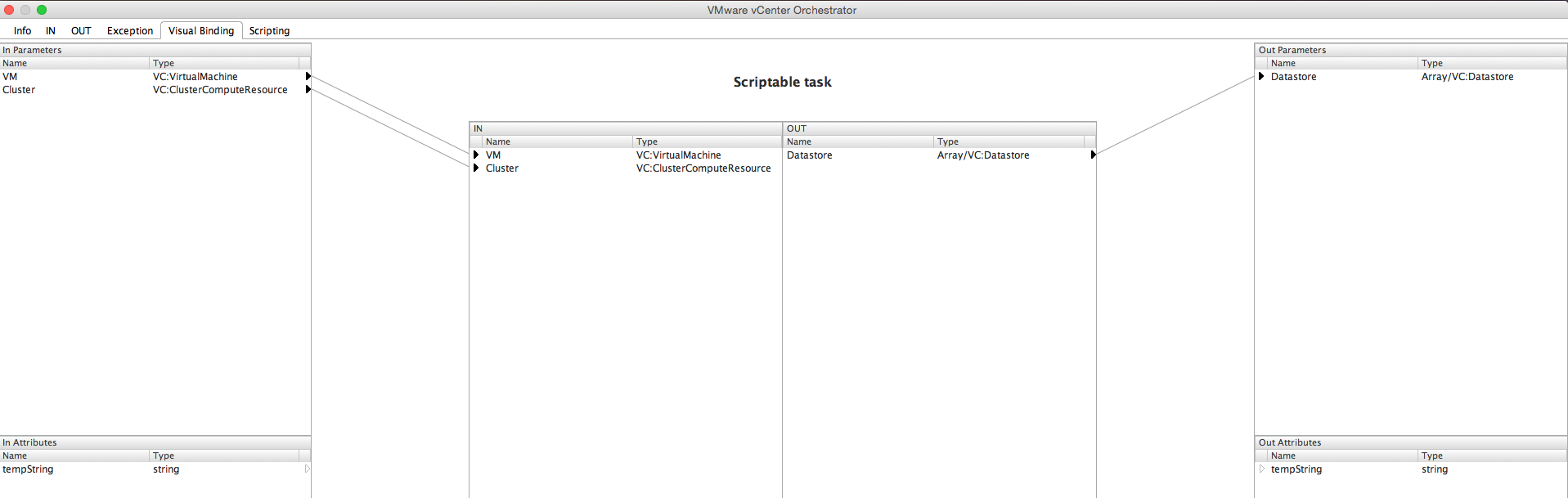
Assuming you created an input Cluster, navigate to scriptable task, Visual Binding tab and drag and drop Cluster to this:

Go to Scripting tab and type the following in:
if (VM && Cluster) {
System.log("Please specify either VM or Cluster");
} else if (VM) {
System.log(VM.datastore);
} else if (Cluster){
System.log(Cluster.datastore);
}
What this scriptable task does it:
- If VM and Cluster specified, it asks the user to specify either VM or Cluster
- If VM is specified, outputs datastore(s) attached to this VM
- If Cluster is specified, outputs datastore(s) attached to this Cluster



Output
Next bit will be output. Once more, refer to the above example. This time, rather than displaying output directly, I am going to save the datastore property to an output.
First of all edit the workflow, navigate to Outputs tab and create an output parameter called Datastore with Array of VC:Datastore type:
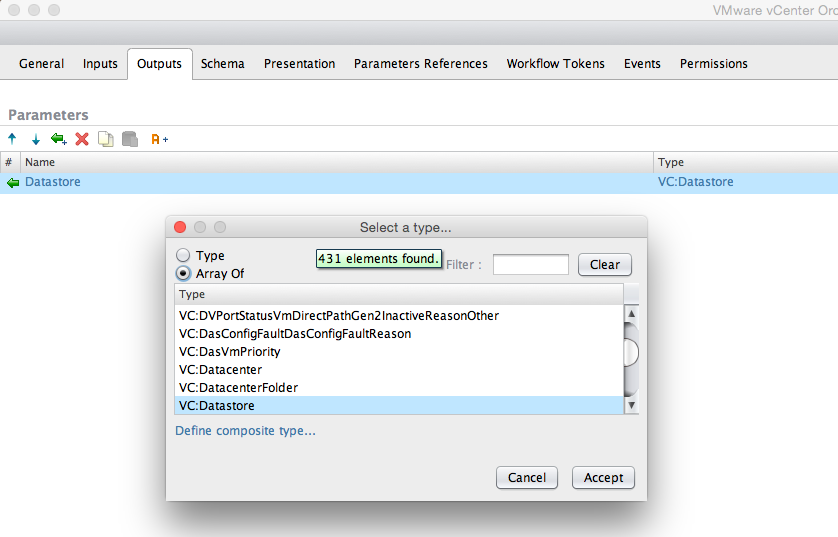

Edit scriptable task and modify the existing script to the following:
if (VM && Cluster) {
System.log("Please specify either VM or Cluster");
} else if (Cluster) {
Datastore = Cluster.datastore;
} else if (VM){
Datastore = VM.datastore;
}
OK then you will say how do I output Datastore? The thing is, this output is the output of this workflow meaning, you will need to create another workflow and use this output as an attribute. An example will be provided in the next series for now, let me start discussing attributes.
Attribute
What is attribute? I personally want to call it “global variable” which can be defined in the beginning or set during workflow run. The reason I want to call it global variable is because when a value is given to it, it could be used anywhere within a workflow. So in summary:
- Attribute could be pre-defined, i.e. input to a workflow
- Attribute could be defined by a scriptable task, i.e. output to a workflow
Time for exercise!
Edit the workflow, navigate General tab and click Add attribute:


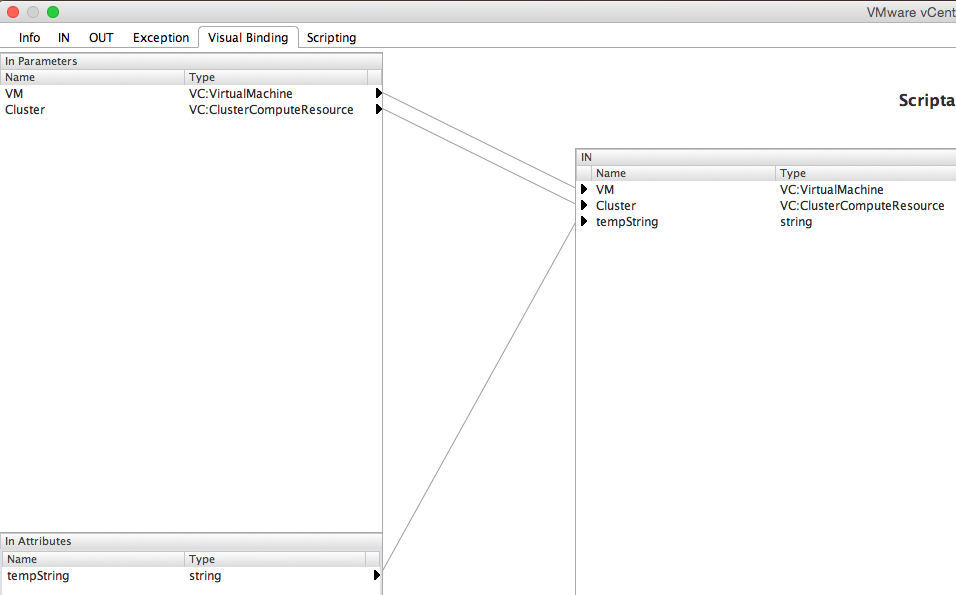
As mentioned earlier, the value for input attribute should be pre-defined otherwise the default value will be ‘’, which is null!
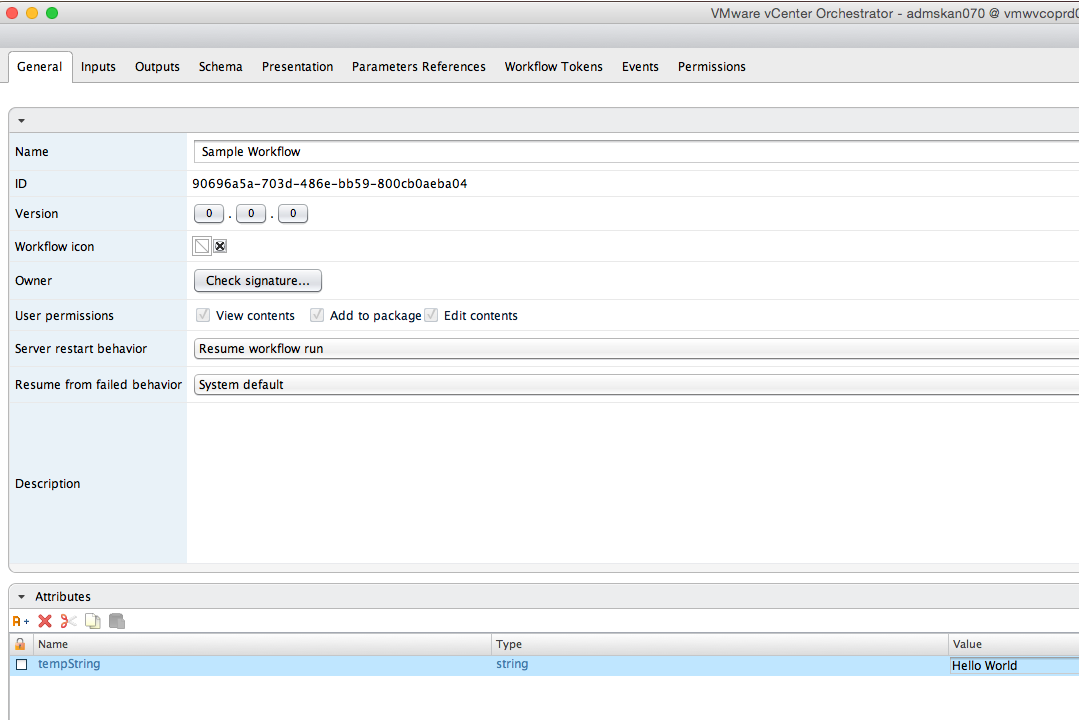
System.log(tempString);
And running the workflow will give you the following:

The exercise we’ve just went through shows you how to pre-define an attribute and output it in the workflow. In this case, the attribute is set to “Hello World” type to String and it could be called anywhere within this workflow. Literally, you can create 10 scriptable tasks and use this value in all of them.
Next one will be output attribute, where you can give a value to it within the workflow.


Next one will be migrating an output parameter to attribute. Instead of creating an attribute manually, you can always migrate an existing input or output parameters to attributes. Go to Outputs and click on attributes which will automatically move output to an attribute:
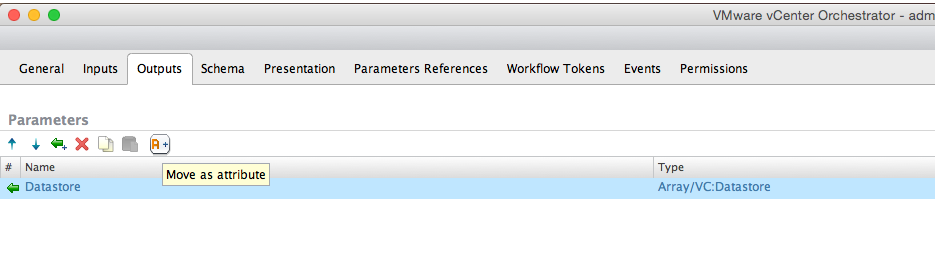

You will see Datastore is now moved to attributes. Go back to scriptable task, navigate to Visual Binding tab and drag and drop Datastore to Out box:

Then add the following in at Scripting field:
if (VM && Cluster) {
System.log("Please specify either VM or Cluster");
} else if (Cluster) {
Datastore = Cluster.datastore;
} else if (VM){
Datastore = VM.datastore;
}
Let’s go back to this statement above:
The thing is, this output is the output of this workflow meaning, you will need to create another workflow and use this output as an attribute.
This time, rather than saving Datastore as an output of the workflow, now the output is from a scriptable task. This means it could be used anywhere within this workflow.
Let me show you how to do this. Drag and drop one more scriptable task just after the original scriptable task:
This time, drag and drop Datastore from Input Attributes:

On the second scriptable task, type the following in Scripting field:
System.log(Datastore);
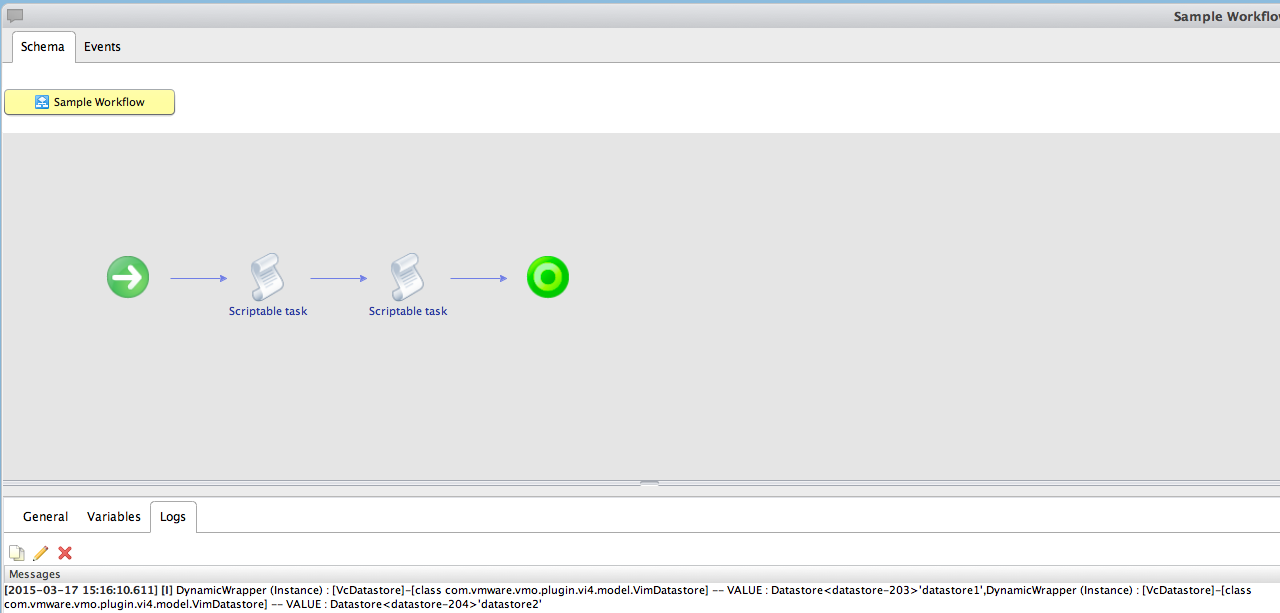
The output is same as last time but the difference now is that:
- Saved datastore output to Datastore object as an attribute
- Parsed the attribute to a scriptable task and presented this value
The purpose of this exercise was to make you familiar with attribute as moving on, this will be used most of the time.
Wrap-Up
Hope this series helped and always welcome to leave a reply below or Twitter for any clarifications.
As mentioned in introduction, the next series will be Action & Workflow. Stay tuned!

