Introduction
I’ve been doing some migration work for the last few weeks and found an interesting behaviour of vMotion that I would like to share with you.
Migration Scenario
The migration work was quite simple, just had to vMotion a few virtual machines from a cluster to another due to SQL licensing.
The end-users wanted the migration to happen live but they were OK with a few packets loss.
As there were shared storage available, it’s been decided to use vMotion + storage vMotion.
Infrastructure
The following is how the vSphere infrastructure was setup for the migration:
- Two clusters
- Source_Cluster
- Destination_Cluster
- 4 x 5.5 ESXi servers per cluster
- 2 x 10Gbe network uplinks
- Management and vMotion VMKernels in different subnet
- Different dvSwitches for clusters
- All 8 ESXi servers in source and destination clusters were with active/active on the physical interfaces, i.e. No LAG.
- Shared storage between clusters were available
Pre-requisites
There was only one element needed to be prepared for the migration, shared dvSwitch between clusters. Just like last time (the blog can be found here), it’s been decided to pull one uplink out from source ESXi server which will be used for the migration. Here after, I will call ESXi_Source_Migration and ESXi_Destination_Migration for the ESXi servers purposed for migration. The following is how it looked like:
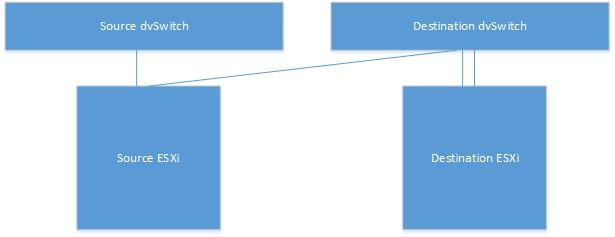
Then the problem was that the vMotion VMKernels were in different subnet:
- Source_Cluster => 192.168.168.x/24
- No Gateway, layer 2 network
- Destination_Cluster => 10.10.21.x/24
- No Gateway, layer 2 network
After a discussion, it’s been decided to add one more vMotion VMKernel to ESXi_Source_Migration with the subnet 10.10.21.x so that the vMotion could happen between the source ESXi servers using 192.168.168.x subnet and between ESXi_Source_Migration and ESXi_Destination_Migration using 10.10.21.x subnet. Figure is attached below:
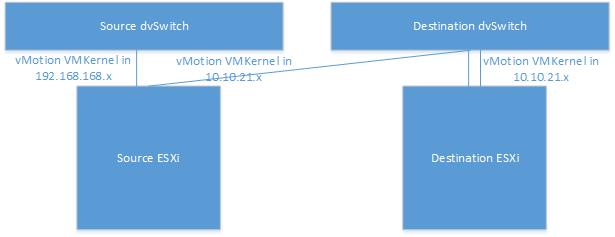
Result
The first virtual machine tried to migrate was not in ESXi_Source_Migration hence it’s been vMotioned to this ESXi server and vMotion was successful. Then I kicked off the migration to ESXi_Destination_Migration. After a few minutes, the process was stuck at 14% and eventually failed saying 192.168.168.x VMKernel cannot talk to 10.10.21.x VMKernel. Error is attached below:
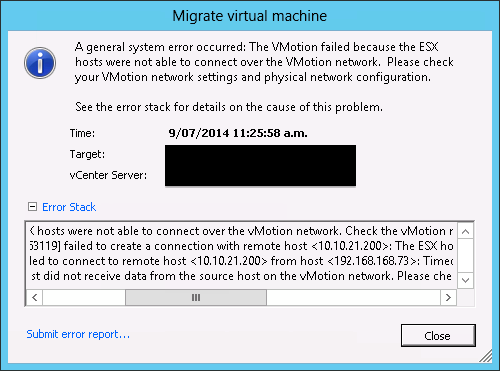
What I thought was that when a virtual machine was being migrated from ESXi_Source_Migration to ESXi_Destination_Migration, it should have been using vMotion VMKernel in 10.10.21.x subnet so that it can talk to the destination.
The quick fix was to remove 192.168.168.x vMotion VMKernel from the source ESXi server and it worked.
After the migration’s finished, added 192.168.168.x VMKernel back to the source ESXi server and was about to start the second virtual machine. It was also located in different ESXi server in source cluster so I vMotioned it to ESXi_Source_Migration. Interesting thing happened, it failed. The vMotion in the same cluster wasn’t successful saying the following:
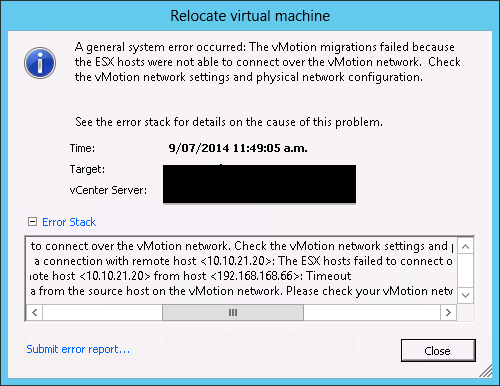
10.10.21.x VMKernel was being used, not 192.168.168.x. Here again, 10.10.21.x VMKernel was removed which allowed the vMotion to be accomplished.
Summarising the result above:
- First virtual machine was vMotioned to ESXi_Source_Migration (successful)
- Performed vMotion + storage vMotion to ESXi_Destination_Migration (failed)
- Removing 192.168.168.x vMotion VMKernel fixed the issue
- After the migration, added 192.168.168.x vMotion VMKernel back to ESXi_Source_Migration
- Tried to vMotion second virtual machine within the cluster to ESXi_Source_Migration (failed)
- Removing 10.10.21.x vMotion VMKernel fixed the issue
With the result above, it’s could be concluded that vMotion uses only one vMotion VMKernel and the latest one that was active before.
Workdaround
Since removing/adding vMotion VMKernels wasn’t an ideal process, it’s been decided to change the destination vMotion VMKernels in 192.168.168.x subnet.
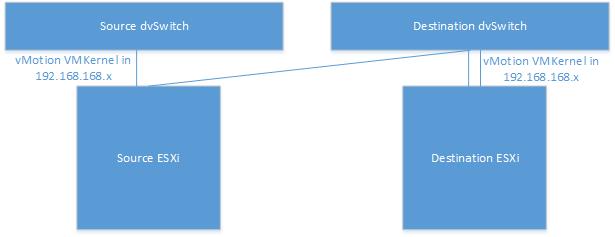
After modification, inter/intra cluster vMotion worked fine.
Wrap-Up
Even though it’s possible to add multiple vMotion VMKernels, apparently it’s not supported in this situation. Probably this is something VMware could improve in future to support this.
For now, using the vMotion VMKernels in the same subnet would be the best & easiest option.

