Introduction
VMware Metro Storage Cluster is defined as:
vMSC is a certified configuration for stretched storage cluster architectures. A vMSC configuration is designed to maintain data availability beyond a single physical or logical site. A storage device configured in the vMSC configuration is supported after successful vMSC certification.
The benefit vMSC provides is simple. When a disaster happens at one datacentre, HA kicks in and fails over virtual machine to another datacentre automatically. It’s a normal vCenter server cluster with HA/DRS enabled but half ESXi servers are in one datacentre and the rest are in another datacentre.
We deployed vMSC with HP 3PAR peer-persistence functionality (more details could be found here). Before putting it into production, performed functional testing to ensure it works as expected and during a certain testing, found an interesting behaviour with 3PAR.
- Clustering Deepdive 5.1
- This is a must if you are a VMware administrator, vMSC is at the last section
- http://blogs.vmware.com/vsphere/2012/05/vsphere-metro-storage-cluster-white-paper-released.html
- http://www.yellow-bricks.com/2012/11/13/vsphere-metro-storage-cluster-uniform-vs-non-uniform/
- http://longwhiteclouds.com/2013/11/08/vsphere-metro-stretched-cluster-with-vsphere-5-5-and-pdl-autoremove/
- http://h20195.www2.hp.com/V2/GetPDF.aspx%2F4AA4-7734ENW.pdf
Infrastructure
- 2 x physical datacetres
- Datacentre_A and Datacentre_B
- 2 x vCenter servers
- vCenter_A and vCenter_B
- A for Datacentre_A and B for Datacentre_B
- 1 x Metro Storage Cluster
- Located in vCenter_A
- Multiples of ESXi servers
- ESXi_A, ESXi_B… and so on
- Only 2 are shown in the figure below
- 2 x 7400 3PAR
- Storage_A and Storage_B
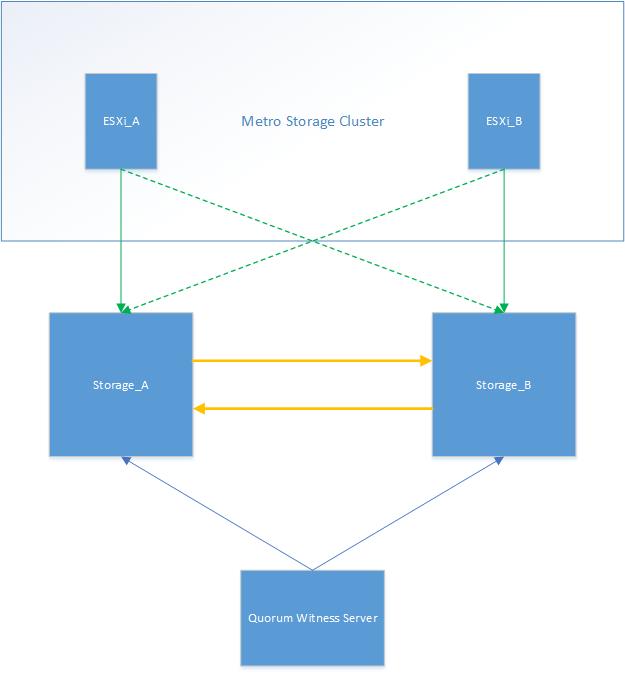
Overall architecture is attached below (it’s a very high level diagram, detailed one could be found in introduction references):
- Green line represents the FC connection between ESXi server and 3PAR storage
- Green dotted line represents the active/standby FC connection between ESXi server and 3PAR storage
- Yellow line represents the replication link between 3PAR storages
- Blue line represents the network connection between 3PAR storages and Quorum witness server
Assumption
- Virtual machines are uniformly accessing datastores. For instance, virtual machine running in ESXi_A uses Storage_A.
- Disk.AutoremoveOnPDL is set to 0 and VMkernel.Boot.terminateVMOnPDL to true.
- A script attached below could be used to validate these two advanced settings.
foreach ($esxi in (Get-Cluster -Name “Name of the cluster(s)" | Get-VMHost | sort Name)) {
$advanced_setting = [string]::Join(", ", ($esxi | Get-AdvancedSetting | where {$_.Name -match "Disk.AutoremoveOnPDL|VMkernel.Boot.terminateVMOnPDL" } | %{$_.Name + ":" + $_.Value}))
$esxi | select Name, @{N="Advanced Settings";E={$advanced_setting}}
}
Test Plan
- Disconnect the ISLs between two datacentres, only FC connection
- Disconnect the network link between Quorum witness server and Storage_A
A figure is attached below:

Expected Result
- Storage_A loses connection to Storage_B as well as the Quorum witness server
- To prevent data corruption, Storage_A stops all I/O
- Storage_B fails over from read-only to read/write
- ESXi_A receives PDL sense codes, i.e. H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0 from Storage_A
- HA kills the virtual machines in PDL state and unregister from the inventory
- HA registers killed virtual machines to ESXi_B accessing Storage_B and power-on
Actual Result
Performing the test, interesting behaviour was noticed. All ESXi servers in Datacentre_A were not responding. Re-connecting ESXi server didn’t work, they were hanging.
To investigate into the issue, made a SSH connection to one of the ESXi servers and opened the vmkernel.log. While looking into it, found a few interesting lines (brief summary):
- Could not select path
- Awaiting fast path state update
- No more commands to retry
The log was telling that ESXi servers were keep trying to search for the available path and eventually, it failed to find one. Running esxcfg-mpath -b outputted 4 dead paths and 4 standby paths.
How does ESXi know that it should stop looking for active path? It should receive either PDL or APD sense codes. The next element I looked into was PDL sense codes in the vmkernel.log. I used vCenter Log-Insight to filter by H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0 but couldn’t find any.
To summarise what happened, when Storage_A stopped all I/O from ESXi_A, it did not send PDL sense codes to ESXi_A. As a result, ESXi_A was keep looking for active paths on and on and finally, it failed. This put ESXi servers in not responding state.
The only way to fix this issue was to reboot the affected ESXi servers.
After having a chat with 3PAR engineers, this is a known behaviour and it’s by design meaning that 3PAR won’t send PDL sense codes to ESXi servers when it stops all I/O.
Wrap-Up
This test scenario is a very special case. Losing network connection from the Quorum witness server to only one 3PAR and losing only FC ISLs between 3PARs is highly unlikely to happen. However, important element found in this test is that 3PAR doesn’t send PDL sense codes when it stops I/O to prevent data corruption. So in future, if this happens, rebooting all ESXi servers should be executed ASAP instead of waiting for HA to failover virtual machines automatically.
